پایداری سرویس در VDI؛ راهنمای کامل جلوگیری از قطعی میزکار مجازی
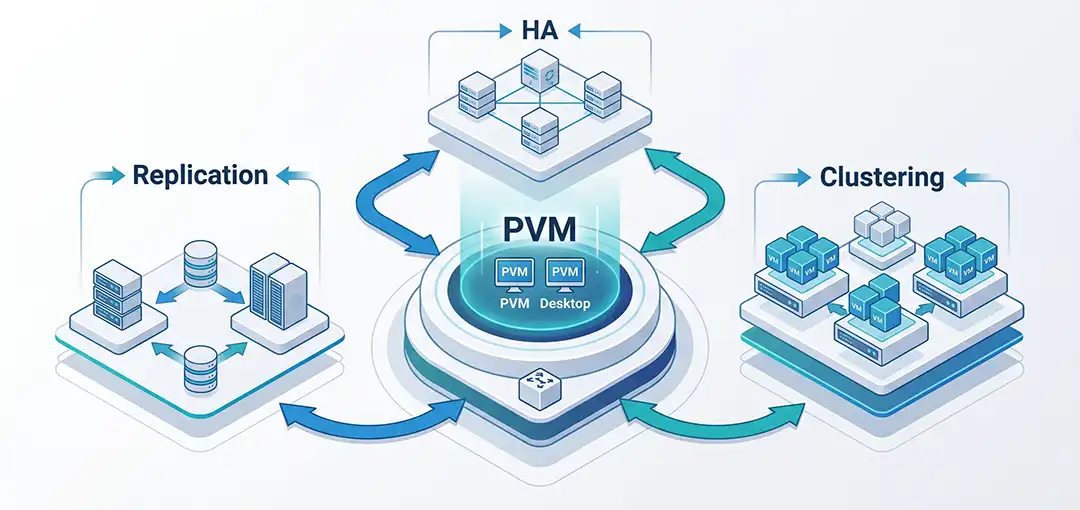
مقدمه: چرا پایداری سرویس در VDI یک الزام است، نه یک انتخاب؟
در دنیای سازمانهای امروز، هر دقیقه توقف سرویس یک هزینه دارد. این هزینه گاهی مالی است، گاهی اعتباری و گاهی عملیاتی. وقتی میزکار کاربران از کار میافتد، نهتنها بهرهوری کاهش پیدا میکند، بلکه زنجیرهای از مشکلات آغاز میشود: تماسهای پشتیبانی، تأخیر در پروژهها، از دست رفتن دادههای ذخیرهنشده و در موارد حساستر، اختلال در خدمترسانی به مشتریان یا ذینفعان.
در مدل سنتی «یک کامپیوتر برای هر کاربر»، خرابی یک دستگاه تنها به یک کاربر آسیب میرساند. اما در زیرساختهای متمرکز مانند VDI، اگر طراحی پایداری سرویس در VDI بهدرستی انجام نشده باشد، یک نقطه خرابی میتواند همزمان دهها یا صدها کاربر را تحت تأثیر قرار دهد.
این دقیقاً همان نقطهای است که مفاهیم دسترسپذیری بالا (HA)، خوشهبندی (Clustering) و تکثیر داده (Replication) اهمیت پیدا میکنند. این سه قابلیت، ستونهای اصلی معماری پایدار در هر زیرساخت سازمانی هستند.
نکته کلیدی: پایداری سرویس در VDI به این معنا نیست که هیچوقت مشکلی پیش نمیآید. به این معناست که وقتی مشکل پیش میآید، سرویس بهصورت خودکار یا با حداقل تأخیر ادامه پیدا میکند.
اگر با مفهوم میزکار مجازی و تفاوت آن با روشهای سنتی آشنایی کامل ندارید، پیشنهاد میکنیم ابتدا مقاله از دسکتاپ سنتی تا VDI؛ مقایسهای دقیق برای انتخابی آیندهنگر را مطالعه کنید.
مفاهیم بنیادین: دسترسپذیری بالا، خوشهبندی و تکثیر داده چیستند؟
قبل از ورود به جزئیات فنی، باید تمایز و ارتباط این سه مفهوم را بهدرستی درک کنیم. این سه مفهوم اغلب با هم به کار میروند، اما هرکدام رویکرد و هدف متفاوتی دارند:
| مفهوم | هدف اصلی | سطح عملکرد | پاسخ به چه سؤالی؟ |
|---|---|---|---|
| High Availability (دسترسپذیری بالا) | حداقلسازی زمان توقف | سرویس | چطور سرویس بدون وقفه باقی بماند؟ |
| Clustering (خوشهبندی) | توزیع بار و تحمل خرابی | زیرساخت | چطور چند سرور مثل یک سیستم واحد کار کنند؟ |
| Replication (تکثیر داده) | تکثیر و نگهداری داده | داده | چطور دادهها در چند نقطه نگه داشته شوند؟ |
این سه مفهوم مکمل یکدیگرند. در بسیاری از زیرساختهای مجازیسازی، خوشهبندی بستر اجرای دسترسپذیری بالا را فراهم میکند و تکثیر داده لایه نهایی محافظت از اطلاعات را تشکیل میدهد.
دسترسپذیری بالا (HA) و نقش آن در پایداری سرویس در VDI
تعریف دقیق دسترسپذیری بالا
High Availability یا دسترسپذیری بالا، مجموعهای از روشها، ابزارها و معماریهاست که هدف آن کاهش حداکثری زمان توقف غیرخواسته (Unplanned Downtime) یک سرویس است.
HA بر اساس یک اصل ساده بنا شده است: هیچ نقطه تکی خرابی (Single Point of Failure) وجود نداشته باشد. یعنی اگر هر جزئی از زیرساخت خراب شود، جزء دیگری بلافاصله وظیفه آن را به عهده بگیرد.
معماری Active-Passive در مقابل Active-Active
در طراحی دسترسپذیری بالا برای پایداری سرویس در VDI، دو رویکرد اصلی وجود دارد:
معماری Active-Passive

در این مدل:
- Node A در حال سرویسدهی است
- Node B آمادهباش است و فقط در صورت خرابی Node A وارد عمل میشود
- مزیت: سادهتر و هزینه کمتر
- معایب: منابع Node B در حالت عادی استفاده نمیشود
معماری Active-Active

در این مدل:
- هر دو Node در حال سرویسدهی هستند
- بار بین آنها توزیع میشود
- در صورت خرابی یکی، دیگری کل بار را میپذیرد
- مزیت: استفاده بهینه از منابع و پایداری بالاتر
- معایب: پیچیدهتر و نیاز به مدیریت Stateful Sessions
سازوکار جابهجایی خودکار سرویس (Failover)
فرآیند Failover یا جابهجایی خودکار سرویس معمولاً از چند مرحله تشکیل میشود:

- مرحله تشخیص خرابی: سیستم Heartbeat Monitor نبودن سیگنال قلبی از Node را تشخیص میدهد.
- مرحله تأیید خرابی: برای جلوگیری از Split-Brain، اجماع گرههای سالم بررسی میشود (Quorum Check).
- مرحله انتقال سرویس: Node جایگزین فعال میشود، ماشینهای مجازی راهاندازی مجدد یا Migration لایو انجام میشود و IP های Float منتقل میشوند.
- مرحله اطلاعرسانی: هشدار به مدیر IT ارسال میشود.
چرا دسترسپذیری بالا برای میزکار مجازی حیاتی است؟
در محیط VDI، خرابی یک سرور Hypervisor میتواند بلافاصله روی دهها یا صدها کاربر تأثیر بگذارد. بدون HA:
- همه کاربران آن سرور بهیکباره سرویس را از دست میدهند
- تیم IT باید بهصورت دستی سرور را راهاندازی مجدد کند
- ماشینهای مجازی باید یکبهیک بررسی و بازیابی شوند
- زمان توقف ممکن است از چند دقیقه تا چند ساعت طول بکشد
اما با فعالسازی HA:
- سیستم بهصورت خودکار خرابی را تشخیص میدهد
- ماشینهای مجازی روی گرههای سالم راهاندازی میشوند
- زمان توقف به چند دقیقه یا ثانیه کاهش پیدا میکند
- کاربران معمولاً تنها یک وقفه کوتاه تجربه میکنند
برای درک بهتر تفاوت عملکرد VDI نسبت به روشهای سنتی، مقاله مقایسه PVM Desktop (VDI) آوید با ایستگاههای کاری سنتی را مطالعه کنید.
خوشهبندی (Clustering): قدرت اجماع در زیرساخت

تعریف خوشه (Cluster)
یک Cluster مجموعهای از سرورها (گرهها / Nodes) است که با یکدیگر هماهنگ میشوند تا بهعنوان یک سیستم واحد عمل کنند. از نگاه کاربران و سرویسها، یک Cluster مثل یک کامپیوتر بزرگ و قدرتمند به نظر میرسد.
اجزای اصلی یک خوشه
| جزء | نقش | اهمیت |
|---|---|---|
| Nodes | سرورهای عضو Cluster | پایه محاسباتی |
| Cluster Network | شبکه داخلی هماهنگی گرهها | ارتباطات Heartbeat |
| Shared Storage | ذخیرهسازی مشترک | دسترسی به داده از همه گرهها |
| Cluster Manager | نرمافزار مدیریت Cluster | تصمیمگیری، Failover و Scheduling |
| Quorum | مکانیزم اجماع | جلوگیری از Split-Brain |
مفهوم اجماع (Quorum) و چرایی آن
یکی از مهمترین چالشهای خوشهبندی، پدیدهای به نام Split-Brain است. تصور کنید یک Cluster سهگرهای دارید و ارتباط شبکهای بین دو گروه از گرهها قطع میشود. در این حالت، هر دو طرف ممکن است سعی کنند سرویس را در اختیار بگیرند که منجر به تداخل و خرابی داده میشود.

راهحل این مشکل است. هر گره برای اتخاذ تصمیمهای مهم باید رأی اکثریت گرهها را داشته باشد. مثلاً در یک Cluster سهگرهای، حداقل ۲ گره باید با هم در ارتباط باشند تا بتوانند تصمیم بگیرند.
انواع خوشهبندی بر اساس کاربرد
- خوشه محاسباتی (Compute Cluster): اجرای ماشینهای مجازی بر روی یک استخر منابع مشترک. Scheduler ماشینهای مجازی را بهصورت هوشمند بین گرهها توزیع میکند.
- خوشه ذخیرهسازی (Storage Cluster): ذخیرهسازی توزیعشده و مقاوم در برابر خرابی.
- خوشه شبکه (Network Cluster): توزیع بار شبکه و افزایش پهنای باند.
جابهجایی زنده ماشین مجازی (Live Migration): قابلیت طلایی خوشهبندی
یکی از مهمترین مزایای خوشهبندی برای پایداری سرویس در VDI، قابلیت Live Migration است. این قابلیت اجازه میدهد یک ماشین مجازی در حالی که در حال اجراست و کاربر دارد از آن استفاده میکند، از یک گره به گره دیگر منتقل شود.

فرآیند به این صورت است:
- حافظه RAM ماشین به Node مقصد کپی میشود
- تغییرات جدید RAM نیز به Node مقصد ارسال میشود
- در یک لحظه کوتاه (معمولاً کمتر از ۱ ثانیه) کنترل به Node مقصد منتقل میشود
- VM روی Node مقصد ادامه میدهد و کاربر تغییری احساس نمیکند
این قابلیت برای موارد زیر ضروری است:
- نگهداری پیشگیرانه سرورها بدون توقف سرویس
- توزیع مجدد بار در ساعات اوج استفاده
- جابهجایی ماشینها قبل از تعویض سختافزار
برای آشنایی بیشتر با خوشهبندی در PVM، وبینار آموزشی کلاسترینگ در سامانه مجازیسازی سرور PVM را مشاهده کنید.
سایت بحران (Replication): تضمین تداوم سرویس
تعریف سایت بحران
Replication فرآیند کپیبرداری و همگامسازی مداوم دادهها از یک محل (Source) به محل دیگر (Destination) است. هدف اصلی آن تضمین وجود یک نسخه بهروز از دادهها در مکان دیگری است، بهگونهای که در صورت از دست رفتن منبع اصلی، بتوان از نسخه کپیشده استفاده کرد.
: تضمین تداوم سرویس")
انواع رپلیکیشن بر اساس زمانبندی
رپلیکیشن همزمان (Synchronous Replication)
در این روش، داده همزمان به هر دو محل نوشته میشود و تأیید به کاربر فقط بعد از دریافت تأیید از هر دو Storage ارسال میشود.
- مزایا: هیچ دادهای از دست نمیرود (RPO = 0)؛ در صورت خرابی Primary، دادههای Replica کاملاً بهروز هستند
- معایب: تأخیر بیشتر در عملیات نوشتن؛ نیاز به شبکه با پهنای باند بالا؛ مناسب برای فاصلههای جغرافیایی کوتاه
رپلیکیشن غیرهمزمان (Asynchronous Replication)
در این روش، تأیید فوری به کاربر ارسال میشود و داده بعداً و با تأخیر به محل دوم ارسال میشود.
- مزایا: تأخیر کمتر برای کاربر؛ مناسب برای فاصلههای جغرافیایی بلند؛ هزینه شبکه کمتر
- معایب: احتمال از دست رفتن دادههای آخرین لحظه (RPO بزرگتر از 0)
انواع رپلیکیشن بر اساس سطح

- سطح Storage: تکثیر مستقیم بلوکهای دیسک. مستقل از نوع داده یا سیستمعامل. کارایی بالا اما نیاز به Storage مشترک.
- سطح Hypervisor: تکثیر ماشینهای مجازی بهصورت کامل. مدیریت از طریق پلتفرم مجازیسازی. انعطافپذیری بالا.
- سطح Application: تکثیر دادههای خاص یک اپلیکیشن مثل Database Replication. هوشمندتر اما وابسته به اپلیکیشن.
رپلیکیشن در سناریوهای تداوم کسبوکار
رپلیکیشن نقش محوری در برنامهریزی تداوم کسبوکار (BCP) دارد. دو سناریوی اصلی وجود دارد:
سناریوی سایت گرم (Hot-Standby)
سایت اصلی و سایت پشتیبان بهصورت مداوم با Replication همگام هستند. در صورت خرابی سایت اصلی، کاربران به سایت پشتیبان هدایت میشوند. دادهها کاملاً همگام هستند و زمان بازیابی در حد دقایق است.
سناریوی سایت ولرم (Warm-Standby)
در این سناریو، دادهها تکثیر میشوند اما سیستمها در سایت پشتیبان کاملاً راهاندازی نشدهاند. زمان بیشتری برای راهاندازی نیاز است اما هزینه کمتری دارد.
اگر میخواهید بدانید چرا تداوم کسبوکار اینقدر اهمیت دارد، مقاله تداوم کسبوکار و همچنین تجربه ۴۰ روز جنگ: چرا دیتاسنتر ریکاوری حیاتیتر از همیشه است؟ را مطالعه کنید.
تعامل سه لایه در یک معماری یکپارچه برای پایداری سرویس در VDI
نقش هر لایه
لایه اول – خوشهبندی:
- اجرای ماشینهای مجازی روی استخر منابع مشترک
- مدیریت بار و توزیع هوشمند ماشینها
- Live Migration برای نگهداری بدون توقف
لایه دوم – دسترسپذیری بالا:
- نظارت مداوم بر سلامت گرهها
- تشخیص خودکار خرابی
- Failover اتوماتیک ماشینهای مجازی
لایه سوم – تکثیر داده:
- همگامسازی دادهها با سایت پشتیبان
- تأمین امکان بازیابی از فاجعه (Disaster Recovery)
- پشتیبانی از سناریوهای چندسایتی
سطوح محافظت در معماری یکپارچه
| سطح | نوع محافظت | راهحل |
|---|---|---|
| سطح ۱ | محافظت در برابر خرابی دیسک | RAID در Storage |
| سطح ۲ | محافظت در برابر خرابی سرور | HA در Cluster |
| سطح ۳ | محافظت در برابر خرابی همه سرورها | Cluster + Shared Storage |
| سطح ۴ | محافظت در برابر خرابی سایت | Replication به سایت پشتیبان |
| سطح ۵ | محافظت در برابر خطای انسانی | Backup و Snapshot |
پیادهسازی پایداری سرویس در VDI با PVM و PVM Desktop
تا اینجا مفاهیم نظری را بررسی کردیم؛ اما سؤال اصلی سازمانها این است:
«این قابلیتها در عمل چطور پیادهسازی میشوند؟»
PVM (Persian VM) بهعنوان اولین و تنها هایپروایزور بومی کشور با سابقه عملیاتی ۱۵ ساله، این سه قابلیت را نه بهعنوان افزونه جانبی، بلکه بهعنوان بخشی یکپارچه از معماری اصلی خود ارائه میدهد. این سامانه دارای تأییدیه امنیتی افتا و پدافند غیرعامل بوده و بهعنوان شرکت دانشبنیان تولیدی نوع ۱ شناخته شده است.
دسترسپذیری بالا در PVM: از تئوری تا اجرا
پیکربندی HA در سطح ماشین مجازی
یکی از تمایزهای مهم PVM این است که تنظیمات HA در سطح تکتک ماشینهای مجازی قابل اعمال است. مدیر سیستم میتواند مستقیماً در فرم تنظیمات هر ماشین مجازی، رفتار آن را در شرایط بحران مشخص کند:
- Always ON: ماشین در هر شرایطی روشن میماند
- Auto Start: در هنگام راهاندازی سرور خودبهخود راهاندازی میشود
- Bind To Host: میتوان مشخص کرد این VM فقط روی سرور خاصی اجرا شود
- High Availability: در صورت خرابی سرور فعلی، بهصورت خودکار روی گره سالم دیگری روشن شود
این رویکرد گرانولار به مدیر IT اجازه میدهد سیاستهای متفاوتی برای گروههای مختلف کاربران تعریف کند. مثلاً:
- میزکارهای مدیران ارشد: Always ON + HA
- میزکارهای کاربران عادی: HA فعال، Auto Start فعال
- محیطهای آزمایشی: بدون HA (صرفهجویی در منابع)
دیدگاه یکپارچه HA در داشبورد PVM
یکی از قابلیتهای ارزشمند PVM، نمایش وضعیت Backup در کنار وضعیت HA در لیست ماشینهای مجازی است. مدیر میتواند در یک نگاه وضعیت هر دو جنبه از پایداری را مشاهده کند.
دسترسپذیری بالا با هزینه پایین: رویکرد Mirror
PVM امکان پیادهسازی High Availability با استفاده از سیستمهای میرور را با هزینه نسبی پایین فراهم میکند. سازمانهایی که بودجه محدودتری دارند نیز میتوانند از مزایای HA بهرهمند شوند.
خوشهبندی در PVM: جزئیات فنی پیادهسازی بومی
سختافزار پشتیبانیشده
یکی از نقاط قوت مهم PVM برای سازمانهای ایرانی، پشتیبانی از طیف گستردهای از سختافزارها از جمله سرورهای نسل قدیمیتر است:
| نوع تجهیز | جزئیات پشتیبانی |
|---|---|
| سرورهای HP | از نسل G7 و G8 به بالا قابل استفاده در Cluster |
| سرورهای IBM | سرورهای x-Series پشتیبانی میشوند |
| SAN Storage | HP، IBM، NetApp، EMC، Promise، QNAP، Stormax، Open E و... |
| پروتکلهای اتصال | NFS، iSCSI، Fibre Channel (FC) بهصورت کامل |
| Multipath | پشتیبانی از افزونگی مسیر اتصال به فضای ذخیرهسازی |
مزیت کلیدی برای سازمانهای ایرانی: در شرایط محدودیت تأمین تجهیزات، توانایی PVM در کار با سرورهای نسل قدیمیتر (مثل HP G7/G8) به سازمانها اجازه میدهد بدون نیاز به خرید سختافزار جدید، Cluster پایدار راهاندازی کنند.
ذخیرهسازی مشترک مجازی (VSAN) در PVM
PVM قابلیت پیادهسازی VSAN (Virtual SAN) را دارد. این قابلیت امکان تبدیل یک سرور سختافزاری به SAN مجازی را فراهم میکند. دیسکهای محلی سرور توسط PVM VSAN Engine به فضای مشترک Cluster تبدیل میشوند. این قابلیت برای سازمانهایی که نمیخواهند هزینه SAN فیزیکی جداگانه پرداخت کنند، یک گزینه اقتصادی و عملی است.
جابهجایی زنده ماشین مجازی در PVM
در فضای Cluster، PVM از Live VM Migration پشتیبانی میکند. مدیر میتواند این قابلیت را هم برای یک ماشین مجازی خاص و هم بهصورت گروهی اجرا کند. همچنین Storage Migration برای جابهجایی امن دیسک مجازی بدون توقف پشتیبانی میشود.
برای اطلاعات بیشتر درباره Storage Migration، مقاله آموزش Storage Migration در PVM را مطالعه کنید.
یک سناریوی نمونه:
- مدیر، سرور Node 1 را برای نگهداری انتخاب میکند
- PVM تمام VM های Node 1 را Live Migrate میکند
- VM ها بدون قطع سرویس روی سایر گرهها اجرا میشوند
- Node 1 کاملاً خالی است و نگهداری انجام میشود
- Node 1 به Cluster برمیگردد و Rebalancing انجام میشود
نتیجه: کاربران هیچ قطعی را تجربه نکردند.
سوئیچ مجازی توزیعشده (Distributed VSwitch)
زیرساخت شبکه در PVM از Distributed VSwitch به همراه پشتیبانی از VLAN پشتیبانی میکند. در زمان Live Migration، ماشین مجازی بدون مشکل شبکهای جابهجا میشود و VM در هر گرهای که باشد با همان VLAN و سیاست شبکه کار میکند.
تکثیر داده و بازیابی از فاجعه در PVM
معماری تکثیر داده در PVM
PVM یک زیرسیستم کامل Disaster Recovery دارد. قابلیت Replication نسخهای بهروز از ماشینهای مجازی سایت اصلی را در سایت دوم (سرور یا کلاستری از سرورها) در اختیار قرار میدهد.
ماشینهای مجازی سایت دوم در بازههای کوتاه (مثلاً ۱۵ دقیقه) با سایت اصلی همسانسازی میشوند و کاملاً آماده به کار هستند. در صورت بروز هرگونه مشکل برای سایت اصلی، کافی است این ماشینها روشن شده و در مدار سرویسدهی قرار بگیرند.
استقلال از نوع ذخیرهساز
یکی از مهمترین ویژگیهای تکثیر داده در PVM این است که به هیچ ابزار ذخیرهسازی خاصی وابسته نیست. محلهای پشتیبانیشده شامل Local Storage، SAN Storage، Direct LUN، NAS/NFS و VSAN هستند.
این استقلال یعنی سازمان میتواند بدون نیاز به هماهنگی پیچیده بین دو سایت از نظر نوع Storage، تکثیر داده را راهاندازی کند.
بازههای همگامسازی
PVM امکان تنظیم بازه Replication را فراهم میکند. بازه پیشنهادی ۱۵ دقیقه است اما قابل تنظیم است. اگر بازه ۱۵ دقیقه تنظیم شده باشد و سایت اصلی ۱۲ دقیقه بعد از آخرین تکثیر دچار بحران شود، آخرین نسخه سالم مربوط به ۱۲ دقیقه قبل است.
سیستم پشتیبانگیری در PVM: لایه تکمیلی پایداری سرویس در VDI
در کنار HA، Clustering و Replication، پلتفرم PVM یک زیرساخت Backup کامل داخلی دارد که سه جزء Backup، Restore و Archive را شامل میشود.
ویژگیهای کلیدی
- پشتیبانگیری زنده (Live Backup): بدون توقف ماشین مجازی؛ VM در حال اجرا و Backup همزمان انجام میشود
- انعطاف در وضعیت VM: امکان گرفتن Backup از VM روشن، خاموش یا هر دو حالت
- بهینهسازی فضا: استفاده از فشردهسازی (Compression) و حذف دادههای تکراری (Deduplication)
- بازگردانی (Restore): امکان گزارشگیری از بکآپهای موجود و بازگرداندن آنها. امکان ایجاد ماشین مجازی در فرآیند Restore وجود دارد
- آرشیو (Archive): تهیه نسخه دوم از بکآپها. از استوریج بکآپ بهعنوان مبدا استفاده میشود و بار اضافه برای ماشین مجازی ایجاد نمیکند
زیرساخت Live Backup سامانه PVM در طی ۱۵ سال اخیر اطلاعات کارفرمایان را در مقابل انواع آسیبها محافظت کرده است:
| نوع تهدید | نحوه محافظت |
|---|---|
| بدافزار و باجافزار | نسخههای سالم قابل بازیابی موجود است |
| خرابی سختافزار | Backup روی Storage جداگانه |
| آتشسوزی | Archive روی محل فیزیکی مجزا |
| خطای انسانی | بازگشت به نقطه زمانی دلخواه |
| خرابی سیستمعامل | Restore کامل VM |
برای مطالعه راهنمای کامل پشتیبانگیری، مقاله راهنمای جامع بکاپگیری از میزکارهای مجازی سازمانی با PVM Desktop را مطالعه کنید.
پایداری سرویس در VDI در سطح میزکار مجازی با PVM Desktop
PVM Desktop بهعنوان راهکار میزکار مجازی سازمانی، از تمام قابلیتهای HA و Clustering زیرلایه PVM بهره میبرد و آنها را در سطح میزکار مجازی نیز گسترش میدهد.
تأثیر HA بر کاربران
بدون PVM Desktop HA: اگر سروری که میزکار ۸۰ کاربر روی آن اجرا میشود خراب شود، ۸۰ کاربر بهیکباره سرویس را از دست میدهند، ۸۰ تماس همزمان با Helpdesk ایجاد میشود و زمان توقف ممکن است ساعتها طول بکشد.
با PVM Desktop + HA: PVM خرابی را در عرض چند ثانیه تشخیص میدهد، میزکارهای مجازی به گرههای سالم منتقل میشوند و زمان توقف به حداقل ممکن کاهش پیدا میکند.
تکثیر داده برای میزکارهای حساس
در PVM Desktop میتوان Replication را برای گروههای مختلف با بازههای متفاوت فعال کرد:
- گروه مدیران ارشد: Replication هر ۵ دقیقه
- گروه واحد مالی: Replication هر ۱۵ دقیقه
- گروه کارشناسان: Replication هر ۳۰ دقیقه
- گروه کاربران عمومی: Backup روزانه (بدون Replication)
مانیتورینگ و لاگ: پیشنیاز پایداری پیشگیرانه
پایداری واقعی نه فقط به ابزارهای Failover، بلکه به مانیتورینگ پیشگیرانه نیاز دارد. PVM در این زمینه قابلیتهای جامعی ارائه میدهد:
- ثبت متمرکز رخدادها: تمام فعالیتها و رویدادها بهصورت دقیق ردیابی میشوند
- ارسال به SIEM: لاگها قابل ارسال به سیستمهای SIEM سازمان هستند
- هشداردهی فعال: ارسال رخدادهای سیستم از طریق SMS و ایمیل
- اطلاعات بلادرنگ: رابط کاربری وب PVM (پلایوید) اطلاعات بلادرنگی درباره وضعیت سیستم ارائه میدهد
سناریوهای عملیاتی پایداری سرویس در VDI

سناریوی اول: خرابی سرور در ساعات اوج کاری
وضعیت: یک سرور از ۳ سرور PVM Cluster در ساعت ۱۰ صبح خراب میشود.
- ساعت ۱۰:۰۰ – سرور شماره ۲ خراب میشود
- ساعت ۱۰:۰۰:۱۰ – PVM Heartbeat Monitor خرابی را تشخیص میدهد
- ساعت ۱۰:۰۰:۳۰ – Quorum تأیید میکند: سرور واقعاً از دسترس خارج شده
- ساعت ۱۰:۰۰:۳۵ – PVM HA شروع به Restart میزکارهای مجازی میکند
- ساعت ۱۰:۰۲:۰۰ – اکثر میزکارها روی Node 1 و 3 در حال اجرا
- ساعت ۱۰:۰۲:۱۵ – SMS هشدار به مدیر IT ارسال میشود
- ساعت ۱۰:۰۵:۰۰ – کاربران دوباره متصل شدهاند (زمان توقف: حدود ۵ دقیقه)
نتیجه: مدیر IT با آرامش سرور خراب را بررسی میکند، بدون فشار «الان همه کار متوقف شده».
سناریوی دوم: نگهداری پیشگیرانه بدون توقف سرویس
وضعیت: یکی از سرورهای PVM نیاز به بهروزرسانی Firmware دارد.
- سرور ۱ به حالت Maintenance Mode قرار میگیرد
- PVM، میزکارهای مجازی را Live Migrate میکند به سرور ۲ و ۳
- سرور ۱ کاملاً خالی میشود و میتوان آن را خاموش کرد
- بهروزرسانی Firmware انجام میشود
- سرور ۱ راهاندازی و به PVM Cluster اضافه میشود
- Rebalancing: میزکارها دوباره توزیع میشوند
نتیجه: نگهداری کامل بدون حتی ۱ ثانیه توقف برای کاربران.
مقاله نجات اطلاعات در بحران؛ تجربهای واقعی از بازیابی زیرساخت نمونهای واقعی از بازیابی اطلاعات در شرایط بحرانی را روایت میکند.
شاخصهای کلیدی پایداری سرویس در VDI: معیارهای SLA و بازیابی
توافقنامه سطح سرویس (SLA)
| SLA | زمان توقف مجاز در سال | زمان توقف مجاز در ماه |
|---|---|---|
| 99% | ۸۷.۶ ساعت | ۷.۳ ساعت |
| 99.9% | ۸.۷۶ ساعت | ۴۳.۸ دقیقه |
| 99.99% | ۵۲.۵ دقیقه | ۴.۳۸ دقیقه |
| 99.999% | ۵.۲۵ دقیقه | ۲۶.۳ ثانیه |
برای دستیابی به هر سطح SLA با PVM:
- 99%: یک سرور PVM با Backup داخلی
- 99.9%: PVM Cluster با HA (حداقل ۲ گره)
- 99.99%: PVM Cluster + Replication + سایت DR
- 99.999%: معماری پیچیدهتر + تمام لایههای فوق
زمان بازیابی (RTO) و نقطه بازیابی (RPO) در PVM
| هدف | راهحل PVM | توضیح |
|---|---|---|
| RTO کمتر از ۵ دقیقه | Active-Active Cluster + Sync Replication | برای سرویسهای بحرانی |
| RTO کمتر از ۳۰ دقیقه | PVM HA Cluster + Async Replication | سطح سازمانی استاندارد |
| RTO کمتر از ۴ ساعت | PVM Backup + سایت Warm Standby | مناسب اکثر سازمانها |
| RPO = 0 | Synchronous Replication | بدون از دست دادن داده |
| RPO = ۱۵ دقیقه | PVM Async Replication | حالت پیشفرض DR در PVM |
| RPO = روزانه | PVM Backup روزانه | کافی برای دادههای کمتغییر |
برای درک بهتر اهمیت پشتیبانگیری منظم، مقاله دستورالعمل پشتیبانگیری از اطلاعات و مدیریت نسخهها را مطالعه کنید.
چالشهای رایج و راهحلهای عملی
چالش اول: Split-Brain در خوشهبندی
مشکل: جدا شدن گرههای PVM Cluster از یکدیگر به دلیل قطع شبکه داخلی.
راهحلها در PVM:
- شبکههای جداگانه: PVM از چند NIC برای Heartbeat پشتیبانی میکند
- Multipath: اتصال به Storage از چند مسیر تضمین میشود
- Bind To Host: تنظیم این پارامتر برای VM های حیاتی
چالش دوم: ظرفیت ناکافی در زمان Failover
مشکل: بعد از خرابی یک گره، سایر گرهها ظرفیت کافی ندارند.
راهحل: رعایت اصل N+1 در طراحی Cluster. اگر ۳ سرور دارید، هر سرور نباید بیش از ۶۶ درصد ظرفیت خود را استفاده کند.
چالش سوم: هزینه بالای تکثیر همزمان
راهحل ترکیبی با PVM: استفاده از رویکرد Tiered Replication:
- میزکارهای حیاتی: PVM Replication هر ۵ دقیقه
- میزکارهای مهم: PVM Replication هر ۱۵ دقیقه (حالت پیشفرض)
- میزکارهای عادی: PVM Backup روزانه (بدون Replication)
چالش چهارم: مهاجرت از راهکارهای قبلی
مشکل: سازمانی که از VMware یا Hyper-V استفاده میکند، چطور به PVM مهاجرت کند؟
راهحل PVM:
- پشتیبانی از استاندارد OVA/OVF: VM های VMware/Hyper-V را به OVA تبدیل کنید و مستقیماً به PVM Import کنید
- قابلیت Migration داخلی: PVM امکان مهاجرت یکپارچه از VMware و Hyper-V را فراهم میکند
- آزادی مهاجرت (Lock-in صفر): آوید مستند مهاجرت از PVM به سایر هایپروایزورها را نیز ارائه داده است
اگر از VMware استفاده میکنید، حتماً مقاله آینده مجازیسازی در ایران؛ چرا زمان مهاجرت از VMware فرا رسیده است؟ را مطالعه کنید.
سخن پایانی
در دنیایی که سازمانها بیش از پیش به زیرساخت دیجیتال وابستهاند، پایداری سرویس در VDI دیگر یک ویژگی لوکس نیست. این یک الزام کسبوکاری است.
- دسترسپذیری بالا میگوید: «اگر یک چیز خراب شد، بقیه ادامه میدهند»
- خوشهبندی میگوید: «چند سرور مثل یک سیستم هوشمند با هم کار میکنند»
- تکثیر داده میگوید: «دادهها در یک نقطه نیستند که با از دست رفتن آن نابود شوند»
PVM این سه ستون را با ۱۵ سال تجربه عملیاتی، پشتیبانی مستقیم بومی، تأییدیههای امنیتی رسمی و یکپارچگی با اکوسیستم آوید ارائه میدهد. برای سازمانهایی که به دنبال پایداری واقعی هستند و نمیخواهند آینده زیرساخت خود را به وابستگیهای خارجی بسپارند، PVM و PVM Desktop یک انتخاب جدی و قابل اتکاست.
دانلود نسخه جامع و کامل مقاله
"*" زمینه های مورد نیاز را نشان می دهد





